结构体
结构体
从4个阶段理解
第一阶段:为什么要用结构体?
想象一下,你要编写一个程序来管理学生信息。每个学生有:姓名、年龄、分数。
如果不使用结构体,你可能需要这样定义变量:
1 | |
痛点:
- 数据零散:
name1和age1在逻辑上属于同一个人,但在代码中它们是毫无关系的独立变量。 - 管理困难:如果有100个学生,你得定义300个变量,甚至建立3个独立的数组。一旦要通过函数传递一个学生的信息,你需要传3个参数。
解决方案: 我们需要一种机制,能够把不同类型的数据(char, int, float)打包到一个“盒子”里。这个“自定义的盒子类型”,就是结构体(Structure)。
第二阶段:结构体的定义与创建
结构体的学习分为两步:先画图纸(定义类型),再盖房子(定义变量)。
1. 定义结构体类型(画图纸)
这只是告诉编译器这个“盒子”长什么样,不占用内存。
1 | |
2. 定义结构体变量(盖房子)
有了图纸,我们就可以在内存中分配空间了。
1 | |
第三阶段:如何操作结构体(访问与赋值)
1. 访问成员:点操作符 .
我们可以通过 . 来读取或修改结构体内部的数据。
1 | |
2. 这里的“深坑”:字符串赋值
初学者最容易犯的错误:
1 | |
第四阶段:结构体的高级用法(数组与指针)
1. 结构体数组(学生花名册)
如果要管理全班同学,我们不需要定义 s1, s2, s3...,而是使用数组。
1 | |
2. 结构体指针与箭头操作符 ->(核心重点)
在C语言中,结构体往往占用较大内存。如果直接在函数间传递结构体变量,会进行值拷贝(复制整个结构体),效率很低。
通常我们传递结构体的地址(指针)。
1 | |
总结口诀:
- 结构体变量用点
.(s1.age) - 结构体指针用箭头
->(p->age)
第五阶段:实战演练(综合代码)
让我们把上面的知识串起来,写一个函数来修改学生的分数。
1 | |
进阶:你需要知道的“内存对齐” (Memory Alignment)
这通常是面试题或底层开发关注的点。
问题: 下面的结构体占用多少字节?
1 | |
你可能以为是 1 + 4 = 5 字节。 但实际上用 sizeof(struct Data) 输出,结果通常是 8 字节。
原因: CPU 为了读取速度更快,不喜欢访问“不对齐”的地址。编译器会自动在 char c 后面填充 3 个空闲字节(Padding),让 int i 从 4 的倍数地址开始存放。
扩展
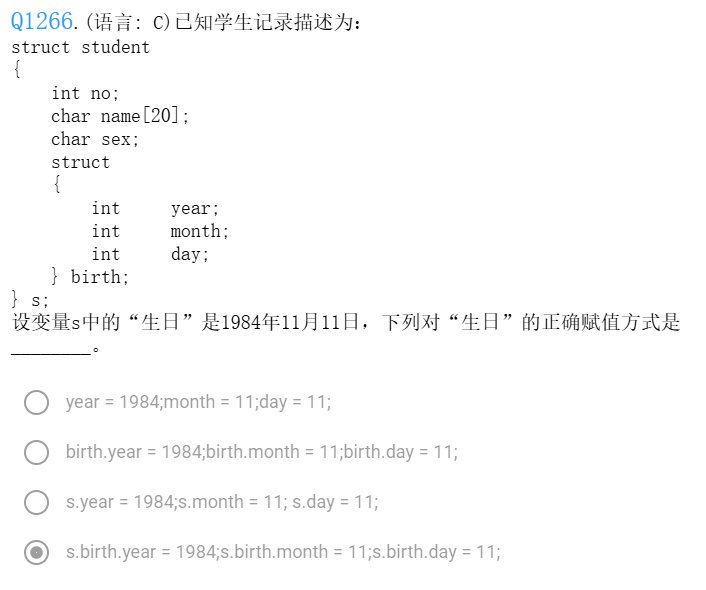
这张图片里的代码它同时用到了C语言结构体的两个“骚操作”:定义时声明变量 和 嵌套匿名结构体。
1. 定义时声明变量
——这是“画完图纸立刻盖房子”。
结构体定义(struct student { ... })通常只是“画图纸”,不占内存。但如果你在定义的结尾、分号的前面写上名字(这里的 s),就意味着:
在定义 struct student 类型的同时,直接创建一个名为 s 的变量。
它等价于下面这两行代码的合并:
1 | |
这种写法的特点:
- 省事:少写一行代码。
- 局限:通常这个
s会变成一个全局变量(如果在main函数外面定义),或者你只想用这一次。
2. 为什么内层 struct 后面没有名字,直接是大括号?
——这是“匿名结构体”作为成员。
注意看内层的这一段:
1 | |
- 没有类型名(匿名):
struct后面空的,说明程序员觉得:“这个日期的结构体太简单了,我不需要给它起个专门的名字(比如struct Date),反正我就在这个student里面用一次,外面也不用。” - 只有变量名:大括号后面的
birth是这个内部结构体的变量名(或者叫成员名)。
这意味着:student 里有一个成员叫 birth,它本身又是一个包含了年月日的小结构体。
3. 如何像剥洋葱一样访问数据?
弄懂了上面两点,这道题的答案就呼之欲出了。我们要给“生日的年份”赋值,必须一级一级地找下去,就像剥洋葱或者俄罗斯套娃:
- 第一层(最外层变量):找到学生变量
s。 - 第二层(中间成员):在
s里找到负责生日的成员birth。- 写法:
s.birth
- 写法:
- 第三层(最内层数据):在
birth里找到年份year。- 写法:
s.birth.year
- 写法:
所以,正确的赋值路径是: s (学生) . birth (生日) . year (年份)